Průnik bitmap množin
Jestli dovolíte, ještě se jednou naposledy vrátím k tématu průniku množin.
(A příště ještě jednou. Reakce na tenhle článek mě utvrdily v tom, že je nekompletní a téma vyžaduje, abych se na něj podíval pořádně a nešířil tu napůl nekompletní moudra. Prostá otázka jak rychle spočítat průnik množin není vůbec prostá a jako vždy záleží na větších či menších detailech. Někdy není třeba chytřejší algoritmus, ale jen lepší implementace hloupého, která bere v potaz charakteristiky hardwaru. Závěry tohohle textu nejsou chybné, jsou jen nekompletní. Bitmapy v případě velkých množin (aspoň těch, které mě zajímají) jsou stále s přehledem nejrychlejší, ale alternativní způsoby můžou být svižnější, než merge algoritmus bez podmíněných skoků, který tady prezentuji jako základní čáru, s níž jsou alternativy porovnávány. Tohle všechno přijde v druhé části článku.)
Pokud mi jde jen o hromadné operace na množinách (průnik, sjednocení, rozdíl a jejich velikosti), mám na výběr ze dvou efektivních reprezentací: Buď jako seřazené pole nebo jako bitmapa. (Ok, není to všechno, ale komprimované verze a další bizarnosti teď vynechám.)
Co se velikosti týká, bitmapa potřebuje tolik bitů jako maximální počet možných prvků, které může obsahovat. Seřazenému poli naopak stačí tolik slov paměti, kolik prvků skutečně obsahuje. Jedno slovo může být například 4B int a pak se z hlediska prostoru bitmapa vyplatí, pokud množina obsahuje více než 1/32 maxima prvků. Ideální je reprezentovat množiny větší než tento limit jako bitmapy a menší jako seřazená pole. To platí pro prostor, ale ne nutně pro rychlost.
Výpočet velikosti průniku mezi dvěma bitmapami je triviální smyčka obsahující
jen add, and a popcnt instrukce.
ulong intersectionSize(BitSet a, BitSet b) { ulong bits = 0; foreach (i; 0 .. a.arr.length) { bits += popcnt(a.arr[i] & b.arr[i]); } return bits; }
Nebo takhle, pokud jste ve spěchu:
ulong intersectionSize(BitSet a, BitSet b) { return zip(a.arr, b.arr).map!(ab => popcnt(ab[0] & ab[1])).sum; }
Operace popcnt je velice rychlá, na Intelích procesorech má latenci 3 takty a propustnost 1 instrukci každý takt. Co jsem se díval k Agnerovi do
tabulek, na Zenech od AMD trvá pouhý jeden takt a má propustnost 4
popcnt v každém taktu. V budoucnu AVX512 přinese tuhle monstrositu a do té doby si musíme vystačit s AVX2 kouzly.
Průnik mezi polem a bitmapou je také záležitost několika triviálních operací zjišťujících, zdali je daný bit nastavený na jedničku.
ulong intersectionSize(BitSet a, uint[] idxs) { return idxs.count!(i => (a.arr[i / 64] >> (i % 64)) & 1); }
Obě varianty jsou jednodušší než průnik mezi dvěma seřazenými poli. Ten porovná dva prvky a inkrementuje ukazatel na menší z nich.
int intersectionSize(uint[] a, uint[] b) { int ai, bi, c; for (; ai < a.length && bi < b.length; ) { auto aa = a[ai], bb = b[bi]; c += (aa == bb); ai += (aa <= bb); bi += (aa >= bb); } return c; }
Je třeba provést mnohem víc instrukcí pro jeden prvek a kód navíc obsahuje datovou závislost mezi iteracemi, kdy adresa dat, které se čtou v jedné iteraci závisí na výsledku vyhodnocení té předchozí. Procesor nemůže plně spekulovat a využít dostupné ILP.
Ve výsledku tak bitmapy můžou být rychlejší, i když nejsou použity ideálně, co se místa týká. Proto tu mám jeden maličký test.
(Existují další způsoby jak udělat to samé, který můžou být mnohem rychlejší, ale v mém testu rychlostí nedokázaly sami o sobě překonat použití bitmap, jen pomohly ve vzájemné synergii.)
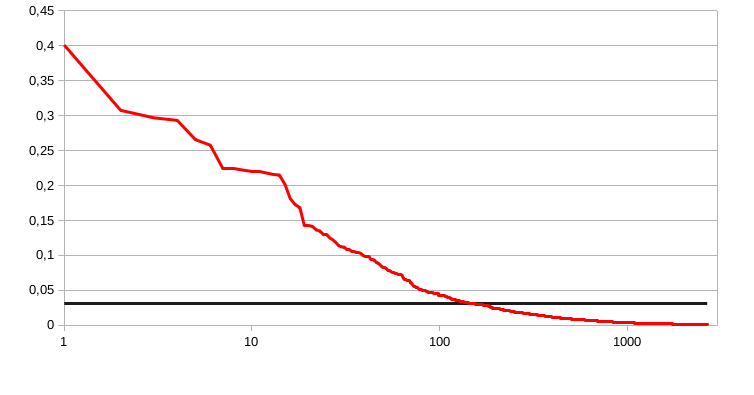
Vzal jsem malý vzorek ze souboru dat pro něž je třeba spočítat podobnost každé množiny s každou další. Obsahuje 2665 množin, rozsah 337229 možných prvků, v součtu mají kardinalitu 8.3 milionu, jedna množina obsahuje průměrně 3126 prvků, detailní charakteristika v grafu. Na logaritmické ose x leží jednotlivé množiny, na ose y je vyobrazena jejich velikost. Vodorovná čára ukazuje mez, nad kterou se vyplatí bitmapy a pod kterou seřazená pole. V tomto případě je to 10538 (337229 * 1/32).
Test počítal velikosti průniků každé množiny s každou další a měnil při tom hraniční velikost pod níž jsou množiny reprezentovány jako seřazená pole a nad kterou jako bitmapy. V prvním řádku mají všechny množiny formu bitmapy i ty maličké, postupně roste počet polí, až na posledním jsou jen seřazená pole.
| hranice | polí | bitmap | čas | * |
| 0 | 0 | 2665 | 42.8 s | všechny množiny jako bitmapy |
| 1/674 | 659 | 2006 | 30.9 s | |
| 1/562 | 916 | 1749 | 28.4 s | |
| 1/482 | 1117 | 1548 | 27.2 s | |
| 1/422 | 1277 | 1388 | 26.9 s | nejrychlejší |
| 1/337 | 1496 | 1169 | 27.8 s | |
| 1/281 | 1645 | 1020 | 29.4 s | |
| 1/241 | 1748 | 917 | 31.1 s | |
| 1/211 | 1835 | 830 | 32.7 s | |
| 1/187 | 1893 | 772 | 34.6 s | |
| 1/169 | 1957 | 708 | 36.8 s | |
| 1/112 | 2155 | 510 | 46.6 s | |
| 1/84 | 2270 | 395 | 55.3 s | |
| 1/67 | 2337 | 328 | 62.3 s | |
| 1/34 | 2498 | 167 | 88.6 s | nejlepší využití místa |
| 1/7 | 2646 | 19 | 159.9 s | |
| 1/3 | 2661 | 4 | 188.3 s | téměř všechny množiny jako seřazená pole |
Je vidět, že varianta zabírající nejméně místa je rychlejší, než když jsou všechny množiny ve formě seřazených polí. Na tom není nic překvapivého a člověk by to čekal, když se musí dotknout nejmenšího množství paměti. Proces ale zrychluje i když jsou jako bitmapy kódovány stále menší a menší množiny. Nejvyšší rychlosti (±9× zrychlení) dosáhnou v bodě, kdy bitmapami reprezentovány množiny 13× menší než ideál.
Operace s bitmapami jsou velice rychlé a vyplatí se je používat, když je to možné. Nejspíš za to může fakt, že využívají jen jednoduché instrukce, které zpracují 64 položek najednou a kód je přímý, bez skoků a datových závislostí. Out-of-order jádro a prefetcher mají volné ruce dělat to, co umějí nejlépe, rozjedou spekulace naplno a můžou dělat mnoho iterací smyčky dopředu.
Jako vždy naměřená čísla berte s rezervou. Můžeme si být jisti jen tím, že platí v daném případě a na daném stroji. Na jiných procesorech a s jinými daty můžou výsledky vypadat jinak. Třeba situace, kdy mám větší počet menších množin, může dopadnout jinak z důvodu paměťové lokality a nižší efektivity prefetcheru. Nicméně nebál bych se používat prostorově ideální rozložení. Nemyslím si, že by mohlo vést ke zpomalení. Možná bych to ještě trochu popostrčil. Ale jako vždy, když na tom záleží, měřte sami a nevěřte číslům na internetu.
K tématu:
Dodatek:
Další varianta je hybridní reprezentace. Když mám data příliš řídká a bitmapa se nevyplatí, nemusí být vše ztraceno. Pokud elementy v množinách mají Zipfovo rozložení, můžu například 64 nebo 128 nejčastějších prvků reprezentovat jako bitmapu a zbytek jako seřazené pole. To také může vést ke zrychlení.